
前回までで、形態素解析ができるようになった。
更に、ツールを使えばすでに構文解析も可能だ。
となると、次のフェーズは意味理解だ。
というわけで、今回は
この意味理解について解説をしていこう。
順番としては、まずは本記事でこの概要を、
次回以降で細かい単位から順番に
意味理解の具体的なお話をしていこう。
必要な補足などあれば、これまでと同様に
別記事で解説したりする…かもしれない。
なお、本講座は以下の本を参考に進めている。
もしよかったら、中身を覗いてみて欲しい。

意味理解
意味理解の必要性
ちょっとだけそもそも論を。
なぜ、この意味理解が必要なのか、という部分だ。
これまでで構造が分かっている。
つまり、その構成している自立語を集めれば、
それが意味になるのではないか、ということだ。
確かに、この方法が取られる場合もある。
しかし、これだけでは不十分な場合も多いのだ。
具体例をお見せしよう。
以下の3文は、全て自立語が共通している。
- 太郎が花子に勉強を教えた。
- 太郎に花子が勉強を教えた。
- 太郎に花子が勉強を教わった。
さて、同じ意味だろうか?
答えは、明らかにNoだ。
このように、自立語だけ見ても、
意味が正確に分類などできるとは言いがたい。
また、もう一つ例文を出そう。
- 太郎が花子に数学を教えた。
これは、「勉強」が「数学」になっていて、
自立語は異なっている。
しかし、内容が具体的になっただけで、
似たような意味だ。
こういったものも、意味を考えない場合には
関連性が理解できない。
こういった部分を補うために、
意味理解が必要なのだ。
意味理解の段階
意味理解には、三つの段階がある。
- 単語の意味理解
- 文の意味理解
- 文章の意味理解
ここからは、これらの概要について見ていこう。
単語の意味理解
以前解説した通り、単語というのは
言語における意味や機能を持つ最小の単位だった。
文の意味を理解するために、
まずはこの単語の意味が分からなければいけない。
意味理解では、各単語、特に自立語が持つ
具体的な意味内容を概念として考え、
これをコンピュータで扱う。
これには三つの方法がある。
- 語彙概念構造
- 概念体系、シソーラス
- コーパスでの使用方法
語彙概念構造
大まかな考え方は、1つの概念を
より細かい要素や概念に分解するというものだ。
語彙概念構造とは、動詞の意味を
基本的な意味要素の組み合わせとして記述するもの。
例えば、上にも出した例に含まれる
「教わる」という動詞を見てみよう。
これには、動作の主体(誰が)、動作の対象(誰に)、
内容(何を)という三つの要素の組が考えられる。
これについては、
本にこれ以上の記載が見当たらなかったので
このくらいに抑えておく。
概念体系、シソーラス
ここでは、類似した概念を
カテゴリーに分類したり、階層的に体系化したりする。
例えば、「少年」や「少女」は「人間」の一種なので、
「人間」というカテゴリに「少年」や「少女」が含まれる、
といった感じだ。
このように階層的に体系化したものを
概念体系、あるいはシソーラスと呼ぶ。
これについては、
別記事でさらに深掘りしていこう。
コーパスでの使用方法
使用方法と書いたが、これは
コーパスでどのように使われているか見る方法だ。
ある単語について、その前後に
どんな単語が来ているかを統計的な傾向として調べ、
それらが注目している単語の意味を表している
という考え方になる。
例えば、「少年」について。
前後には、「学校」とか、「遊ぶ」とか、
こういった単語が多く出てくるだろう。
こういったものから、
「少年」が何なのかを推測するのだ。
これについても、別記事で細かく見ていく。
文の意味理解
文の意味というのは、
一般的に以下の2つから構成されている。
- 命題内容
- モダリティ
命題内容
命題内容とは、その文が記述している
出来事や状況、関係、性質のこと。
述語と、それを修飾する名詞句などによって
表現されるもので、この構造を述語項構造と呼ぶ。
この述語項構造は、
述語論理式というもので表すことができる。
例えば、「太郎が図書館で本を読んだ」という文の
述語論理式を書いてみよう。
$$\exists x \ \exists y \ ( \mbox{read}(\mbox{taro}, x, y) \land \mbox{book}(x) \land \mbox{library}(y) \ )$$
さて、この式の見方を説明しよう。
まず、readという三つの引数を持つ関数は、
一つ目が、二つ目のものを、三つ目の場所で読んだ
という意味だ。
book関数は、その引数が本であること、
library関数は、その引数が図書館であることを表している。
つまり、
太郎がxをyで読んだ、
xが本である、
yが図書館である、
というもの全てが成り立っているということになる。
先頭の\(\exists x\)とか\(\exists y\)とかは、
それぞれ括弧の中を満たすような
\(x\)、\(y\)が存在することを示している。
ここでは、これが変数になると思ってもらっていいだろう。
オマケで、ちょっと複雑にしてみる。
出来事の時制や種類、各項目の役割を明確にしてみよう。
イベント変数と呼ばれる新しい変数\(e\)を導入して、
以下式のように表される。
$$
\begin{eqnarray}
\exists e \ \exists x \ \exists y \ (& \ & \mbox{read}(e) \land \mbox{past}(e) \land \mbox{agent}(e, \mbox{taro}) \land \\
& \ & \mbox{object}(e, x) \land \mbox{book}(x) \land \mbox{place}(e, y) \land \mbox{library}(y) \ )
\end{eqnarray}
$$
こういった述語論理式には、
メリット・デメリットが存在する。
メリットは、厳密性があること、
デメリットは計算が複雑になったり
柔軟性に欠けたりすること。
デメリットの柔軟性を重視する場合、
単純なグラフ構造で表現する方法もある。
同じ文章「太郎が図書館で本を読んだ」という
命題内容は、以下のグラフで示される。
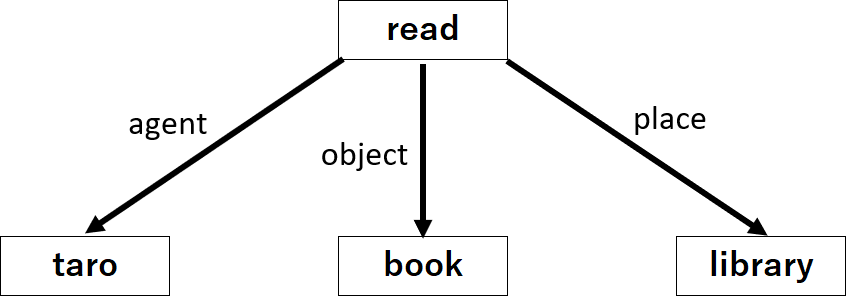
各頂点は述語や項の概念を表し、
矢印のラベルは各項の役割…
これは以前解説した深層格を表している。
深層格については以下を参照してほしい。
自然言語処理勉強結果「日本語の構造」 | Shino’s Mind Archive
モダリティ
モダリティとは、
命題内容に対する書き手の主観的態度だ。
主に動詞の活用形や助動詞などの文末表現
によって表現される。
例えば、文末が「~そうだ」となっていれば、
それは伝聞というモダリティから構成されている
という分析ができる。
このモダリティも二つに分けられる。
一つが対事的モダリティ、これは
命題の内容に対する書き手の判断を表す。
もう一つが対人的モダリティ、
こちらは読み手に対する発話態度だ。
何かのアンケートなど、
意見を分析するような場合には対事的モダリティが、
対話システムなどでは対人的モダリティが重要になる。
文章の意味理解
複数の文が意味的に関連し、
更にそれらがまとまったものが文章だ。
複数の文が作る意味的構造を
談話構造、もしくは修辞構造と呼ぶ。
ここでは、簡単に修辞構造理論
という考え方をご紹介しよう。
この理論では、隣り合った二つの文が
なんらかの意味的関係で結び付けられ、
より大きな意味が形成される、
という考え方になる。
これを繰り返し、文章全体を根とする木が構成される。
この、文間の意味的関係のことを修辞関係と呼び、
以下の種類などに分けられる。
- 詳細:内容を詳細に述べる
- 状況:状況の補足的な情報
- 順列:出来事の時間的順序
- 原因:出来事などの原因
- 結果:出来事などの結果
具体例として、以下の4文からなる文章で見てみよう。
- 先日のテストで、太郎は好成績を収めました。
- 太郎は、最初数学の一分野で苦労していました。
- しかし、参考書を駆使して理解することができました。
- その結果、太郎は志望校のランクを上げることができました。
…適当に考えたので、
細かい部分は気にしないでほしい。
さて、これらの文の関係を見ていこう。
まず、1文目がもとで、4文目が結果となっている。
次に、1分目をもとにし、2文目、3文目が詳細だ。
2文目、3文目の関係は順列となる。
このような考え方が、修辞構造だ。
これを自動的に求める処理を修辞構造解析と呼び、
これには機械学習がよく利用されている。
意味に対する操作
長くなってきたが、もう少しだけ。
上の内容で意味を求めた後、
何をするかという部分だ。
目的に応じて、主に以下3つの内容を行う。
- フィルタリング
- 推論
- 類似性判定
フィルタリング
フィルタリングとは、なんらかの意味的な制約を満たす
単語や文、文章を抽出、あるいは排除する処理のこと。
意味による一般的なフィルタリングと捉えていいだろう。
推論
これは、ある文から推論できる文を求める、あるいは
二つの文が包含関係にあるかを調べる処理だ。
特に包含関係を調べる処理を包含関係認識と呼ぶ。
単語レベルでは、シソーラスがそのまま利用できる。
これに、文の意味も考えることで、
文間の推論を行うのだ。
類似性判定
これは、与えられた二つの文が
どの程度類似しているかを求める処理だ。
通常は、類似度は0以上1以下の実数で表される。
単語や文章のクラスタリング、
情報検索などに応用することができる。
おわりに
キリのいいところまでやってしまったので、
かなり長くなってしまった。
今回は概要レベルなので、
次回から細かい内容に入っていこう。
この意味理解ができれば、
実際の応用もできるようになってくる。
そこまで、是非お付き合いいただきたい。


コメント