
前回は…結局日本語の構造だけで終えてしまった。
今回こそ、本格的に
自然言語処理の内容に入っていこう。
まずは、自然言語の内容を解析しなければいけない。
この解析は、大きく分けると
構造の解析と意味の解析になる。
そのうち、構造の部分について解説していこう。
なお、本講座は以下の本を参考に進めている。
もしよかったら、中身を覗いてみて欲しい。

自然言語解析の概要
一般的に、自然言語の解析は以下の流れで行われる。
- 形態素解析
- 構文解析
- 意味解析
- 文脈解析
今回は、まず構造的な部分の解析までを解説しよう。
具体的には、形態素解析と構文解析の二つだ。
形態素解析
早速前回の用語が出てきた。
復習しておくと、
形態素とは意味を持つ最小の単位だった。
さらに、単語とは厳密には
異なるものであったことも思い出してほしい。
この形態素解析では、
入力されたテキストから、この形態素を抽出する。
これには、以下3つの処理が必要だ。
- 形態素列への分割
- 形態素への品詞付与
- 形態素の原形復元
まず、形態素へ分割しないと解析ができない。
そのため、最初にこの分割を行う。
次に、それぞれの形態素の品詞を判別する。
ここまではいいが、最後の原形復元が若干謎だ。
これは、形態素が活用しているものについて、
その原形を求めることを指す。
例えば、「私は学校へ行きます」という文を
形態素解析してみよう。
まず、形態素へ分割すると、
「私 | は | 学校 | へ | 行き | ます」となる。
つまり、この文は6個の形態素からなるというわけだ。
次に、品詞の付与。
これを行うと、各形態素は以下のように
品詞が付与できる。
| 形態素 | 品詞 |
|---|---|
| 私 | 名詞 |
| は | 助詞 |
| 学校 | 名詞 |
| へ | 助詞 |
| 行き | 動詞 |
| ます | 助動詞 |
最後に、原形復元。
そもそも、この6形態素の中で
活用するのは最後の二つだけ。
「行き」の原形は「行く」、
「ます」はこれが原形だ。
というわけで、
これも表に付け加えると以下のようになる。
| 形態素 | 品詞 | 原形 |
|---|---|---|
| 私 | 名詞 | – |
| は | 助詞 | – |
| 学校 | 名詞 | – |
| へ | 助詞 | – |
| 行き | 動詞 | 行く |
| ます | 助動詞 | ます |
これで、形態素解析が完了だ。
…とはいったものの、
これをじゃあ一般的にどうするんだというお話になる。
そこで、実はこれをやってくれるツールがすでに存在する。
有名なのは、Javaなどで使えるMeCabだろうか。
その他、探してみたら
このMeCabを使えるWebAPIを発見した。
「MECAPI」というものらしい。
以下リンクを貼っておくので、
気になる方は使ってみよう。

構文解析
形態素解析で得られた形態素から、
文の構文構造を求めるのが、構文解析だ。
この構文構造には
句構造、係り受け構造の二種類ある。
句構造
これは、文中の隣り合う形態素を
生成規則によってまとめた木構造だ。
全体を構成する文から、
どのような構造になっているかを細分化していく。
これをどうやって求めるかも、
ツールがあるのでそちらを使おう。
いったん、ここでは例だけ出す。
例文を、
「私は昨日図書館で借りた分厚い本を読んだ」
としよう。
まず、先に形態素解析だ。
それをした結果が以下の通り。
私 は 昨日 図書館 で 借り た 分厚い 本 を 読ん だこれを、構文構造に直す。
実際行う際には生成規則と呼ばれる規則があり、
それに則る形で構造を組み立てていく。
幾つか例を出すと、
文は後置詞句と動詞句に分けられ、
後置詞句はさらに名詞句と助詞に分けられ、
などなど。
なお、後置詞とは
助詞「は」、「を」、「で」などのこと。
後置詞句はよく主語になる「〇〇は」などが該当する。
この生成規則がいくつかあり、
それに当てはまるよう分解していくと、
以下の2パターンが得られる。


一つ目と二つ目で意味が若干変わっているのだが、
分かるだろうか。
一つ目は、「昨日」が「図書館で借りた」という
動詞句にかかっている。
つまり、本を借りたのが昨日で、
それを読んだという意味になる。
それに対し、二つ目では、
「昨日」が「読んだ」という動詞にかかっている。
となると、借りた本を読んだのが昨日ということになる。
このように、まったく同じ文でも、
異なる意味を取れる場合があるので気を付けよう。
係り受け構造
係り受け構造は、文節を一つの塊とみなして、
それが意味的にどこへ結びついているか
を構造化したもの。
復習で、文節とはそこで区切っても
不自然にならない最小単位だった。
例を見てもらった方が早いので、
先に出してしまおう。
上と同じ、
「私は昨日図書館で借りた分厚い本を読んだ」
という文で見ていこう。
まず、文節で区切ってみる。
私は 昨日 図書館で 借りた 分厚い 本を 読んだこれで、各文節がどこに係っているかを
図にしてみよう。
こちらも、「昨日」がどこに係っているかで
二つのパターンがある。
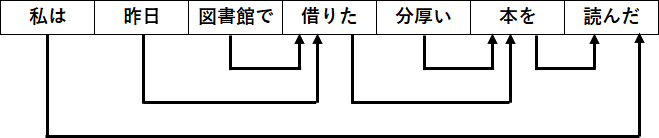
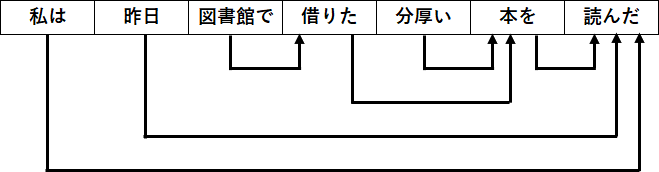
これには、二つほど注意点がある。
まず、一つの文節は、
その右側のいずれか1つに係っている。
上の図でも、矢印が分岐していたり、
同じ文節から複数の矢印が出てることはない。
もう一つ、この矢印が交差することはない。
例えば、「昨日」が「借りた」に係っていて、
かつ「図書館で」が「読んだ」に係っているとすると、
この二つの矢印が交差してしまう。
こういった状態は許されていない。
この条件を、非交差性と呼んだりする。
さて、ここからもう一つ、
係り受け木というものを作ろう。
一番右の文節を根として、
ある文節に係るものを下位の要素として構成する。
上の2パターンをそれぞれ係り受け木に直すと以下の通りだ。
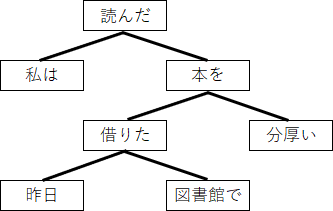
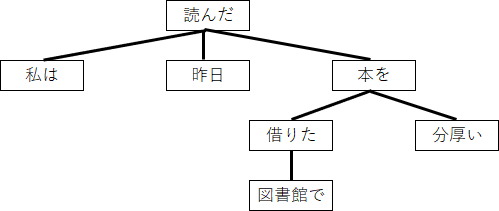
これは、上の矢印で結んでいた構造と比べ、
語順が変わっても木の形が変わらないという点で
優れている。
そのため、語順の自由度が高い日本語であれば、
こちらの方が適している。
構文解析のツール
色々あるが、二つほど。
まず、Javaから使えるCaboCha。
オープンソースで使用可能とのこと、
公式サイトは以下だ。

もう一つ、今度はAPIになるが、
Yahooから日本語の係り受け解析APIが公開されている。
こちらも、公式サイトを紹介しておこう。

こちらも無料で使えるとのこと。
なお、実はYahooには形態素解析を行えるAPIもある。
その使い方までは紹介するか分からないが、
気になる方は覗いてみて欲しい。
おわりに
今回は、自然言語解析のうち、
構造の解析を行う部分を解説した。
意味を理解する前に、
この構造が分からなければいけないので、
何をしているのかしっかり把握しておこう。
次回は、意味の方に進む…と思いきや、
この構造解析を深堀りしていく。
結局ツールを使うのだが、
その中で何をやっているのかを見ていきたい。
ここで、実際のツールの使い方なんかも
紹介しようかと思う。


コメント